
Evolution of Programming Language Traits
Say you need to add some strings together. Maybe you have a word known only at runtime that you need to put inside a sentence. How you do that depends on which language you’re using. For instance, in Fortran, you would use string concatenation:
Sentence = 'If Socrates is human and ' // Property // ', then he is ' // Property // '.'But if you were doing it in Objective-C, you would probably have done it like this:
NSString *sentence = [NSString stringWithFormat:@"If Socrates is human and %@, then he is %@.", property, property];That’s string formatting: putting placeholders in a string and specifying which variables should replace those placeholders at runtime. That works, but these days you’re more likely to write it differently. Today you would probably write it in something like the following manner:
const sentence = `If Socrates is human and ${property}, then he is ${property}.`;This is string interpolation – where variables are inserted directly inside the string – in JavaScript. So here we have three different ways of putting strings together.[1] What is interesting is that they seem to vary in prevalence over time. Specifically, string interpolation seems to have become more and more popular, crowding out string concatenation and string formatting. In JavaScript, it was introduced with ES6 (2015); Scala introduced it in version 2.10.0 (2013):
val sentence = s"If Socrates is human and $property, then he is $property."C# added it in version 6.0 (2015):
string sentence = $"If Socrates is human and {property}, then he is {property}.";Python added f-strings in version 3.6 (2016):
sentence = f"If Socrates is human and {property}, then he is {property}."In other words, many languages started adding string interpolation in the 2010s. My intuitive feeling is that it became popular with Ruby, which alongside Rails began to pick up steam around 2005 (although Ruby was far from the first language to feature it). Here’s how it looks in Ruby:
sentence = "If Socrates is human and #{property}, then he is #{property}."Many new popular languages feature string interpolation, including Dart (2011), Kotlin (2011), Elixir (2011), Julia (2012) and Swift (2014). One that does not is Rust (2010). A GitHub issue created in 2015 in rust-lang/rfcs, which suggests adding string interpolation to Rust, is instructive, as it shows Rust users requesting it, often mentioning having come from some other language which does have it. User vvaidy writes: “I must confess it astonished me when I started in Rust that a modern language did not support string interpolation.”[2]
Edit 2023-07-06: Rust added support for captured identifiers in format strings (essentially, string interpolation) in its 1.58.0 release, announced on 13 January 2022, one year after I wrote this post.
This seems to be a common sentiment and I agree. I for one don’t want to go back to a world where the only way of combining strings is by concatenating them. Having the option of string interpolation seems unambiguously good. So maybe it would be prudent for us to find out what sort of process gave us string interpolation.
We can start doing that by making some observations about the string combination problem:
- Different languages solve this problem in different ways, indeed some languages even solve it in multiple ways, in other words, there is variation.
- Each language supports a limited number of ways of doing it and each programmer uses a limited number of languages, such that each way of combining strings is in a sense pitted against other ways when somebody chooses one to include in a language or use in code, in other words, there is competition.
- New languages (and new versions of old languages) are influenced by older languages, in other words, there is inheritance.
These three qualities – variation, competition and inheritance – are preconditions for evolution; without them, evolution (as described by Darwin) cannot happen.[3] There is at any moment a variety of approaches to string combination, the better ones tend to win out in the struggle for adoption and those that survive in turn influence future approaches. This is an example of evolution of programming language traits, which is itself an example of cultural evolution.
Innovation on a Microscale #
More specifically, the development of string interpolation is an example of innovation, the act of creating new and different things. Though innovation seems to be happening at breakneck speed, there is nothing abrupt about it. Changes are small and cumulative.[4] New ideas are based on old ideas, on recombinations of them and on extending them to new domains.[5] This does not make those ideas any less important. An illustrative example is the lightbulb, the history of which is one of incremental improvement. Because recombination and extension of ideas enables innovation, we can imagine that it’s beneficial to have programmers knowing several languages, paradigms and tools, so that they can transfer ideas between them and combine ideas found in different places.
There is evidence that innovation diffusion normally follows an S-shaped cumulative distribution curve, with a very slow uptake followed by rapid spread followed by a slowing as the innovation nears ubiquity.[6] Joseph Henrich has shown that these curves, which are drawn from real-life data, fit models where innovations are adopted based on their intrinsic attributes (as opposed to models in which individuals proceed by trial-and-error, for example).[7] In other words, in the real world, it seems, innovations spread in the main because people choose to adopt them based on their qualities.
What qualities? Everett Rogers, an innovation theorist (and coiner of the term “early adopter”), identified five essential ones: an innovation must (1) have a relative advantage over previous ideas; (2) be compatible such that it can be used within existing systems; (3) be simple such that it is easy to understand and use; (4) be testable such that it can be experimented with; and (5) be observable such that its advantage is visible to others.[8] String interpolation is all of those things.
Here’s a rough empirical test of the two hypotheses, that (1) string interpolation has become much more prevalent in recent years and (2) its increase in prevalence follows an S-shaped cumulative distribution curve.
I use this PYPL data set to get a measure of the popularity of 28 different programming languages between 2004 and 2020. Then I calculate, for each year, the sum of popularity scores of the languages that supported string interpolation that year as a proportion of the sum of popularity scores of all languages that year. (You can find the R code on GitHub.) Here is the result:
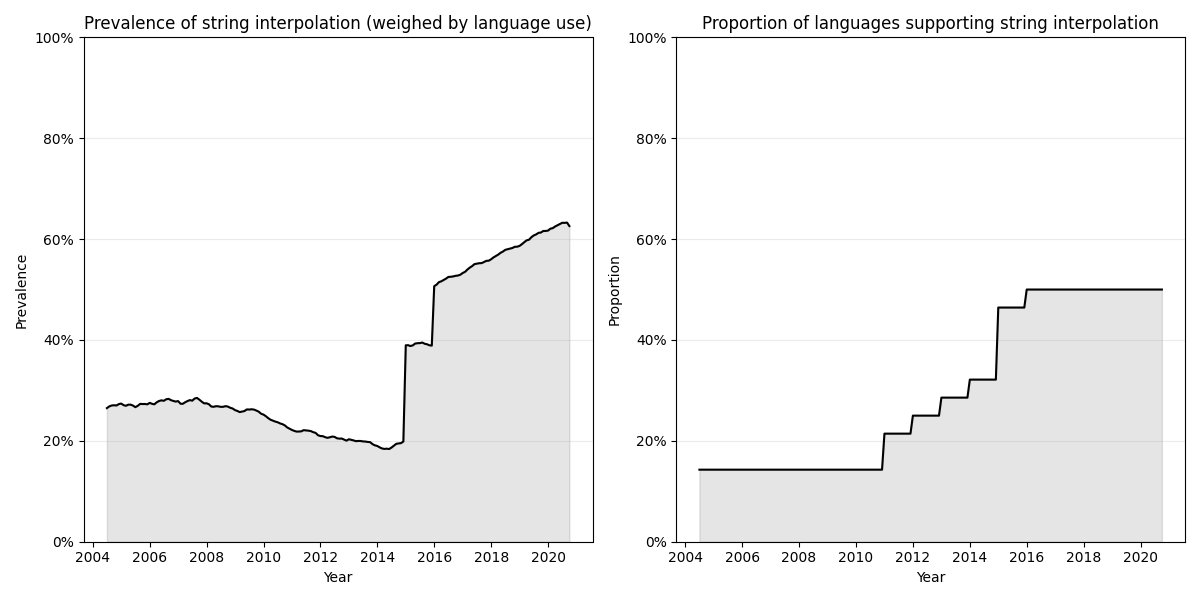
Edit 2023-07-06: I have since updated the plot using a new script written in Python, but the new graphs show essentially the same thing as the old graph.
This admittedly limited approach gives evidence compatible with hypothesis 1 but not with hypothesis 2. There was a gradual drop-off in string interpolation prevalence from 2007–14 as use of two of the main languages supporting it then, Perl and PHP, declined. In 2015–16 there was however a sharp increase in prevalence, as popular languages like C#, JavaScript and Python added support for it. Why do the graphs not show the expected S-shaped curve?
- Maybe the sample size is just too small for us to expect any kind of smooth curve. It’s a pretty noisy signal.[9]
- Maybe it’s that my methodology makes things appear less continuous than they were. For example, Python added support for string interpolation in version 3.6, but it surely took time for Python users to migrate to that version, so in reality access to string interpolation increased more smoothly than my plot shows.
- Maybe there is a different cultural-evolutionary process going on. Natural languages have been found to develop in bursts of change interspersed with periods of relative stasis, what in biology is known as punctuated equilibria.[10] Maybe something similar drives the evolution of programming languages, though if so it’s not clear to me which sorts of events activate those bursts.
Innovation on a Macroscale #
So Meliboeus, carefully set out
Your plants and pear trees, all in rows – for whom?
For strangers, for others, we have farmed our land.[11]– Virgil
The rate of cultural innovation generally is correlated with population size.[12] That makes sense: a country of a million will naturally produce more innovations than a country of one. Simulations indicate that innovation produces far more value in large population groups.[13] So reducing barriers of entry to becoming a programmer is beneficial for everyone in so far as one wants programming to produce more goods (though it can still be detrimental to an individual programmer since programmers compete for scarce goods like prestige, jobs and promotions).
But there’s also another factor that greatly affects the population-level rate of innovation. That factor is not necessity, which the adage calls the mother of invention. (Companies generally cut R&D costs when times are tough, not the other way around.[14]) Neither is it a handful of geniuses making earth-shattering individual contributions.[15] No, what greatly affects a population’s rate of innovation is its interconnectedness, in other words how widely ideas, information and tools are shared.[16] In a culture that is deeply interconnected, where information is widely shared, innovations are observable and shared tools and standards mean that innovations are also more likely to be compatible. Most importantly, interconnectedness provides each individual with a large pool of ideas from which they can select the most attractive to modify, recombine, extend and spread in turn.
Interconnectedness relies on people actually sharing their knowledge, their ideas and tools. This is what free and open source software (FOSS) is all about. Richard Stallman wrote in Why Software Should Be Free:
Software development used to be an evolutionary process, where a person would take an existing program and rewrite parts of it for one new feature, and then another person would rewrite parts to add another feature; in some cases, this continued over a period of twenty years. Meanwhile, parts of the program would be “cannibalized” to form the beginnings of other programs.
The existence of owners prevents this kind of evolution, making it necessary to start from scratch when developing a program. It also prevents new practitioners from studying existing programs to learn useful techniques or even how large programs can be structured.
Why do people contribute to FOSS? Who would have thought, during most of the past century, that a new market would open up to which vast masses of people would contribute their labour freely, avidly and for no apparent benefit? one which enormous corporations, too, would support and fund at no direct profit? and whose ethos would spread into science, agriculture, design, media, the arts and elsewhere? It is rare for people to give away their labour free of charge.
Yet GitHub has >100M hosted repositories.[17] Smartphones, supercomputers, web servers and embedded systems all see Linux and Linux-derived operating systems with the majority of the market share. Regular people contribute to it, corporations sponsor it, governments fund it and the European Commission advocates it. What gives?
There are different answers to this conundrum. Stallman, trying to explain why people should contribute to FOSS, points to pleasure, altruism and alternative funding models among other things. Eric S. Raymond, trying to explain why people do contribute to FOSS, wrote that “[t]he ‘utility function’ Linux hackers is maximizing is not classically economic, but is the intangible of their own ego satisfaction and reputation among other hackers.” In other words, maybe there is a reputation system in which failure to share knowledge is seen as bad and prestige is granted to many of those who do share. Other accounts point to contributors’ signalling to potential employers and, for companies, improving FOSS quality as a way of selling complementary services.[18]
Programming is often seen as a solitary occupation. In fact, programming has its centre in people and is a deeply social occupation, in the sense that not only did we learn to program through other people and content that they made, and not only do we do it now with tools and ideas created by them, but that this learning, these tools and these ideas are in constant change as other people work on improving them, tirelessly, for our benefit, every minute of the hour and every hour of the day.
Footnotes #
There are further differences within these groups. For instance, some languages with string interpolation allow only variables to be inserted, whereas others also allow expressions to be inserted. Other languages allow string formatting, but only when printing to the console. These distinctions are interesting but not relevant for what I want to discuss here. ↩︎
There is now an accepted RFC that proposes adding string interpolation to Rust. ↩︎
Mesoudi, A. (2011). Cultural evolution : how Darwinian theory can explain human culture and synthesize the social sciences. Chicago London: University of Chicago Press. ↩︎
It’s true that there are different thresholds in various techniques and that these techniques are sometimes replaced by new ones with much higher thresholds. But that probably means there was a gradual development happening in another area, which become viable for this application. So while at some point the electronic calculator must have seemed like a large and sudden improvement over the abacus and the mechanical calculator, it was the product of a gradual development of computers until at a certain point they became a viable alternative in the calculating aid niche. ↩︎
Brien, M. & Shennan, S. (2010). Innovation in cultural systems : contributions from evolutionary anthropology. Cambridge, Mass: MIT Press. ↩︎
Henrich, J. (2001). Cultural Transmission and the Diffusion of Innovations: Adoption Dynamics Indicate That Biased Cultural Transmission Is the Predominate Force in Behavioral Change. American Anthropologist, 103(4), 992–1013. ↩︎
ibid. ↩︎
Rogers, E. (2003). Diffusion of innovations. New York: Free Press. ↩︎
These is an additional problem, too. The sudden increase around 2015–16 can partly be explained by the method I used, assuming as it does that all users of a language always use the latest version of it, which is obviously not the case in the real world, wherefore we should expect string interpolation in the real world to have seen a much more gradual increase starting 2015. ↩︎
Mesoudi, A. (2011). Cultural evolution : how Darwinian theory can explain human culture and synthesize the social sciences. Chicago London: University of Chicago Press. ↩︎
Virgil & Ferry, D. (2000). The eclogues of Virgil : a translation. New York: Farrar, Straus, and Giroux. ↩︎
Shennan, S. (2001). Demography and Cultural Innovation: a Model and its Implications for the Emergence of Modern Human Culture. Cambridge Archaeological Journal, 11(1), 5–16. ↩︎
ibid. ↩︎
Brockhoff, K., & Pearson, A. (1998). R&D Budgeting Reactions to a Recession. MIR: Management International Review, 38(4), 363-376. ↩︎
Brien, M. & Shennan, S. (2010). Innovation in cultural systems : contributions from evolutionary anthropology. Cambridge, Mass: MIT Press. ↩︎
ibid. ↩︎
Some of these are owned or sponsored by for-profit companies or non-profit foundations that pay their developers. But I expect the majority to be unfunded and free and open source. ↩︎
Lerner, J., & Tirole, J. (2003). Some Simple Economics of Open Source. The Journal of Industrial Economics, 50(2), 197–234. ↩︎